
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 총급여세액
- lan
- 네트워크
- network
- paas
- threading
- 취미
- ppt
- 근로소득공제
- Excel
- cloud
- 인형
- 카카오프렌즈
- 인형뽑기
- 연말정산
- 재테크
- 클라우드
- 꾸미기
- Blog
- 무민
- 근로소득
- 금융
- iaas
- 세금
- PowerPoint
- 파워포인트
- gil
- 포켓몬스터
- MultiThreading
- SaaS
- Today
- Total
쿠키의 저장소
Kafka란? - 카프카의 탄생 배경 본문
안녕하세요.
이번 포스팅에서는 Kafka에 대해서 다루어 볼까 합니다.
그동안 회사에서 Kafka를 주먹구구식으로 사용하기만 해보았지 제대로 공부해보진 않았었는데요...
이게 공부를 해야지 해야지 하는데 막상 하려하면 너무 귀찮아서...
그러다보니 종종 팀원분들과 대화를 하는 도중에 "아 제가 카프카를 잘 몰라서" 라는 말을 하게 되는 경우가 생기는데, 더 이상은 이러면 안되겠다는 생각이 들더라구요. 그래서 이제 공부를 해볼까하고 공부하는 내용을 남기고자 합니다.
이번에는 가볍게 탄생 배경부터 알아보고자 합니다.
저는 사실 무엇이든 공부하기 전에 "왜 이것이 필요하게 되었는가?"를 이해하고 넘어가는 것이 가장 좋다고 생각을 합니다.
필요했던 배경을 이해하고 풀어나가고자 했던 문제가 무엇이었는지를 명확히 이해하면 애쓰지 않아도 해당 솔루션의 핵심, 특징을 자연스럽게 이해하게 되기 때문입니다. 본격적으로 알아보기 전에 아래의 그림을 한 번 볼까요?
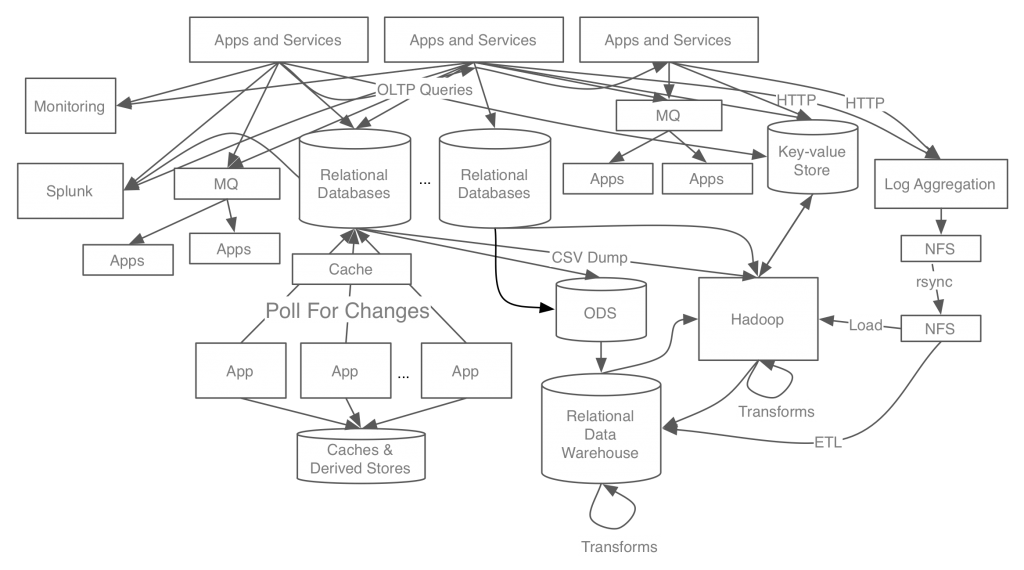
어우.. 쳐다보기만 해도 복잡하고 머리가 아픕니다.
카프카는 링크드인에서 개발이 시작된 미들웨어입니다. 위의 그림은 링크드인이 맞이한 상황을 축약해놓은 것인데요.
뉴스피드나 광고 등 UI 로딩과는 별개로 비동기로 수행되어야하는 작업 등이 늘어나면서 이를 기존의 REST 인터페이스나 MQ로 해결하기가 어려워졌습니다. 실시간 비동기 처리를 위해 사용하던 MQ(Message Queue)가 존재하기는 했지만 한계점이 존재했습니다. ActiveMQ 같은 기존의 MQ는 메세지 전달의 신뢰성 보장에 초점이 맞춰져 있었기 때문에 성능이 굉장히 느렸고 큰 데이터를 처리할 수 없었습니다. 이러한 이유에서 MQ에 저장되는 데이터는 굉장히 축약되어있었기 때문에 해당 MQ로부터 데이터를 받아서 활용할 수 있는 시스템이 한정적이었습니다. MQ의 데이터로는 기능을 수행하기에 충분하지 않았던 시스템들을 위해서는 App/Service 쪽에서 필요한 데이터를 직접 전송해주어야 했고, 이러한 Third-Party 시스템이 늘어갈때마다 App/Service 개발자들은 메인 업무보다도 연동 업무에 의해 더 많은 고통에 시달려야 했습니다.
또한 데이터 파이프라인 관리 측면에서도 굉장한 어려움이 있었습니다. 처음에는 필요한 부서에서 각자 원하는 방식으로 데이터를 주고받도록 개발했고 그것이 불편하다 생각하지 못했습니다. 그러나 점차 요구조건이 늘어나게 되었고 각각의 시스템의 데이터가 연결되어야 할 필요가 생기면서 문제가 발생하기 시작했습니다. 시스템은 이미 너무 복잡하게 구축되어 있었고 각 파이프라인의 데이터 포맷은 각자 너무 다르게 구현되어 있었습니다. 게다가 처리 방식도 완전히 달라서 데이터 파이프라인의 확장이 너무 어려웠습니다. 그러다보니 동일한 데이터를 활용하면서도 효율적이지 못하고 오히려 너무 복잡한 시스템이 되어가는 것을 보며 링크드인에서는 이를 해결해야겠다 생각한 모양입니다. 이에 링크드인에서는 이를 해결하기 위해 "이벤트 스트리밍 플랫폼"이라고 부르는 시스템을 구축하기 시작했습니다. 이것이 지금의 Kafka가 된 것입니다.
링크드인에서는 이러한 이벤트 스트리밍 플랫폼의 용도를 크게 두 가지로 정의하였습니다.
1. 스트림 처리(Stream Processing) : 실시간 데이터에 반응, 처리 또는 변환을 할 수 있어야 합니다.
2. 데이터 통합(Data Integration) : 이벤트 발생 및 데이터 변경을 감지하고 이러한 사항들을 다른 데이터 시스템에 제공할 수 있어야합니다. 흔히 이야기하는 ETL의 스트리밍 버전이라고 이야기할 수 있습니다.
링크드인에서 제시한 위의 두 가지 용도로 사용되는 이벤트 스트리밍 플랫폼은 아래와 같은 구조를 갖도록 고안되었습니다.
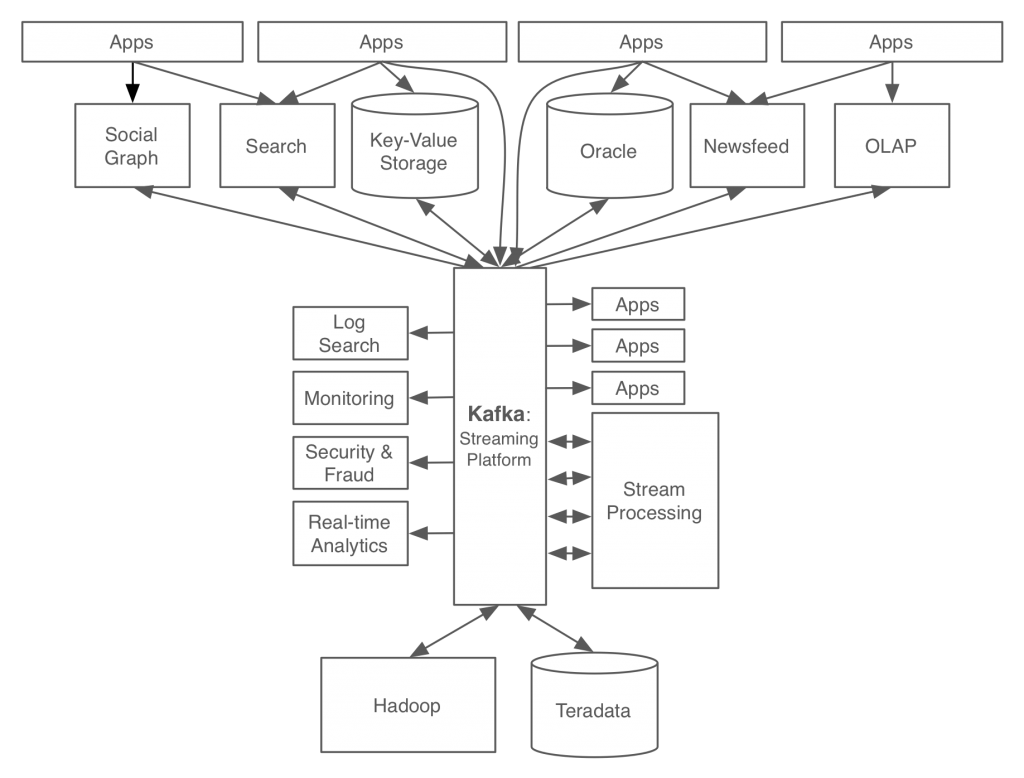
위의 구조를 달성할 수 있게 하기 위해서 링크드인에서는 이벤트 스트리밍 플랫폼이 갖춰야할 기능을 제시하였습니다. 다음은 그들이 제시하는 이벤트 스트리밍 플랫폼의 핵심 기능입니다.
1. 이벤트 스트리밍 플랫폼은 대규모 데이터 스트리밍에 대해서 아래의 요구조건을 만족시키는 실시간 Pub-Sub 기능을 제공해야 합니다.
- 실시간 어플리케이션에서 활용할 수 있도록 single-digit latency를 달성해야합니다.
- 로그 데이터, IoT 또는 외에 여러 용도로 사용되는 대용량 데이터 스트리밍을 처리할 수 있어야합니다.
- 이벤트를 능동적으로 Publish하는 어플리케이션 뿐만 아니라 Database와 같은 수동적 시스템과도 통합이 가능해야합니다.
2. 대규모 스트리밍을 실시간으로 처리(High Throughput)할 수 있어야합니다. 메세지를 최적화하는 등 실시간 스트리밍 처리 기법이 적용되어야 합니다.
3. 대규모의 데이터 스트리밍을 신뢰성있게 저장할 수 있어야합니다. 특히나 다음의 요구조건을 만족시켜야 합니다.
- Database의 변경로그를 Search Index 같은 복제본 저장소(replica store)에 복제하거나 데이터를 손실 없이 순서대로 전달하는 것과 같은 중요한 업데이트를 잘 처리하기 위해서 강력한 복제 기능과 순서 보장 기능을 제공해야합니다.
- 오랜 기간 데이터를 저장하거나 버퍼링할 수 있어야합니다. 이를 통해 이벤트 스트리밍 플랫폼이 주기적으로만 데이터를 로드하는 배치 시스템과 통합될 수 있습니다. 또한 시스템 로직이 변경되었을 때, 데이터가 유지되고 있으므로 재처리가 가능해집니다.
- 이벤트 스트리밍 플랫폼은 시스템이 대규모로 확장될 수 있도록 높은 확장성을 제공해야합니다. 확장 비용이 저렴해야합니다.
이번 포스팅에서는 Kafka가 탄생하게 된 배경 즉, 어떠한 문제에 맞닥뜨렸었는지 어떤 점을 해결하고 싶어했었는지를 알아보았습니다. 또한 이를 위해 어떠한 목표를 세웠는지도 함께 알아보았는데요. 다음 포스팅에서는 그렇게 고안된 Kafka가 어떠한 특징을 가지고 있는지, 기존의 Message Queue 시스템과 어떠한 차이점을 가지고 있는지 한 번 알아보도록 하겠습니다.
포스팅 내용 중에 잘못된 내용을 발견하시면 댓글로 남겨주세요. 확인 후 검토하여 수정이 필요한 부분은 수정하도록 하겠습니다.